Für jeden Job gibt es das passende Werkzeug, für einen Datenmanager bei Netfonds ist PDI häufig das Mittel der Wahl. In dem folgenden Artikel wird ein grober Überblick gegeben, warum PDI ein gutes Allzweckwerkzeug ist und für welche Anwendungsfälle wir die Software nutzen.
Was ist PDI?
PDI, bei uns konkreter PDI-ce oder firmenintern “Pentaho” genannt, steht für das Pentaho Data Integration Toolkit von Hitachi Vantara, welches wir in der Community Edition nutzen. Pentaho ist eine Business Intelligence Software und bietet eine gute Grundlage für ETL-Prozesse (s.U.) und stellt häufig die Datengrundlagen für Geschäftsentscheidungen und Statistiken.
Die Software zeichnet sich durch eine grafische Oberfläche (Spoon) für eine modulare Entwicklung aus und kann bereits ohne tiefgreifende Programmierkenntnisse mindestens ausführend bedient werden. Für komplexere Prozesse ist Wissen über modulare Programmierung, Java und JavaScript sinnvoll, um performante, stabile sowie fehlerfreie Strecken programmieren zu können.
Fertig programmierte Jobs können ohne grafische Oberfläche mittels Pan & Kitchen ausgeführt werden, aber auch ohne großen Aufwand in Spoon direkt. Dies bietet die Möglichkeit ressourcenschonend Jobs zu automatisieren, z.B. über den Windows Scheduler oder wie bei Netfonds über eine eigene Softwarelösung – zu der in Zukunft hier ein kommender Blogpost verlinkt sein wird.
Für Wissbegierige gibt es im Pentaho Ordner einen eigenen Samples Ordner mit interessanten Use Cases um einen Einstieg zu finden. Dieser ist standardmäßig in der Community Edition enthalten.
Die Pentaho-Küche
Die Namensgebung in Pentaho orientiert sich an einer Küche, weshalb das Entwickeln von Jobs auch als Kochen referenziert wird. So gab es passend zum Thema z.B. für ältere Versionen das Pentaho Cookbook.
Die Pentaho-Küche besteht aus drei Elementen, welche Batch oder Shell-Skript ausgeführt werden: Spoon, Pan und Kitchen.
Die grafische Oberfläche wird mittels “Spoon” gestartet und dient zur Entwicklung der Jobs. Hierzu werden die Daten in den “Kettle” geschüttet. Kettle (Kettle Extraction Transformation Transport Load Environment) gilt als Vorgänger von Pentaho und bildet als Java basiertes ETL Tool die Grundlage für alle Funktionen. Über die kettle.properties können global in Pentaho gültige Werte gespeichert werden, die nicht Session oder Job abhängig sind.
Mit der “Pan” können wir fertige Transformationen ordentlich durchbraten ohne die grafische Oberfläche (Spoon) zu starten. Hierzu muss der Transformationspfad in einer eigenen Batch-Datei an Pan übergeben werden. Die Transformation läuft dann auf Konsolenebene.
Um etwas größere Gerichte ohne grafische Oberfläche zu kochen verwenden wir die “Kitchen”. Diese erlaubt uns ganze Jobs auf Konsolenebene auszuführen, ebenfalls indem wir den Pfad als Parameter mit übergeben.
Beispielhafte Konsolenzeile anhand von “kitchen”:C:\\data-integration\\kitchen.bat /file:\"C:\\testordner\\test.kjb\" /level:Basic
Aufbau des Datenflusses in Pentaho
Pentaho unterscheidet zwischen Jobs und Transaktionen:
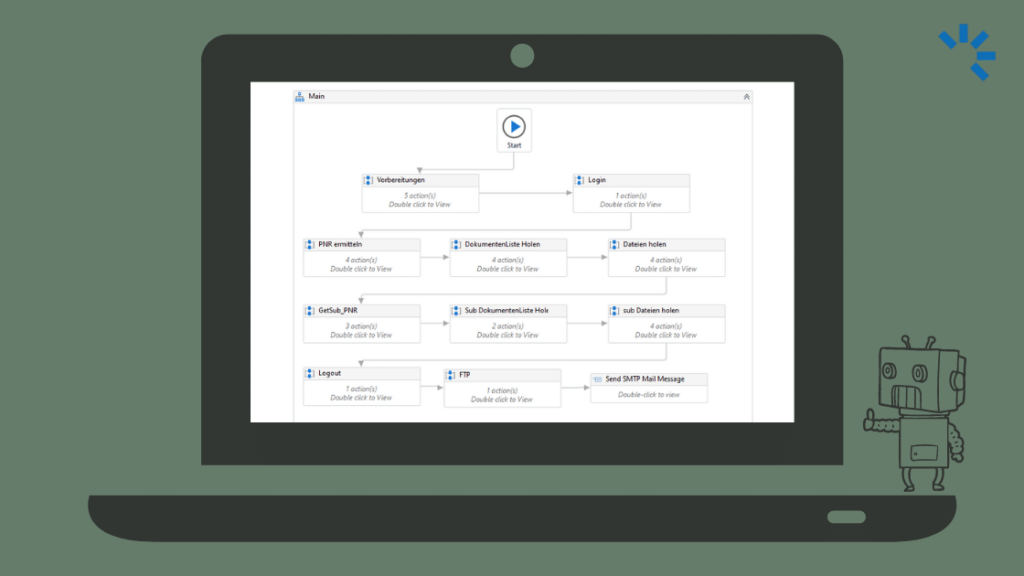
Jobs stellen einen übergeordneten Rahmen für den allgemeinen Flow der Strecke. Ein Job kann z.B. Daten vom sFTP hoch- und herunterladen oder eine Reihe Transformationen ausführen. Außerdem kann man in einen Job einen Unterjob starten der für sich wieder Transformationen beinhaltet kann – also schön verschachtelt.
Transformationen hingegen beziehen sich auf Einzeldatensatz-Ebene um diese zu verarbeiten / verändern, können aber auch einen Unterjob starten, der wiederum Transformationen beinhalten kann.
Ein Job kann mehrere Transformationen haben. Nach mehreren Ebenen steigt Pentaho aus, sodass Jobs und Transformationen nicht unendlich stapelbar sind.
Jeder Job startet immer mit “Start” und endet im Optimalfall mit “Success”
Es kann nur einen Start pro Job geben – Unterjobs haben jeweils ihren eigen Start.
Es kann jedoch mehrere Success oder Abort-Enden geben. Dies wird z.B. benötigt wenn man in bestimmten Fällen noch eine E-Mail verschicken möchte.
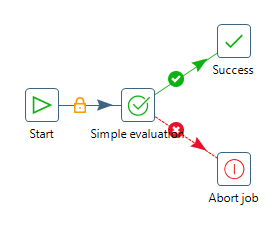
So z.B. kann ein Job, bestehend aus Hauptjob und Unterjob, aussehen. Dieser führt erst 3 Transformationen aus und öffnet dann einen Unterjob. Der Unterjob kann dann eine eigene Transformation enthalten und z.B. eine E-Mail versenden.
Hauptjob

Unterjob
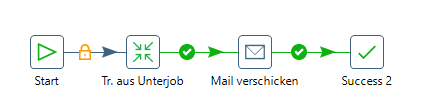
Sowohl im Job als auch in einer Transformation habe ich die Möglichkeit die Datenströme auf verschiedene Wege zu lenken um abhängig von gesetzten Werten spezifische Entscheidungen zu treffen.
Über Filter kann ich z.B. nicht benötigte Daten aussteuern oder Berechnungen ausführen.
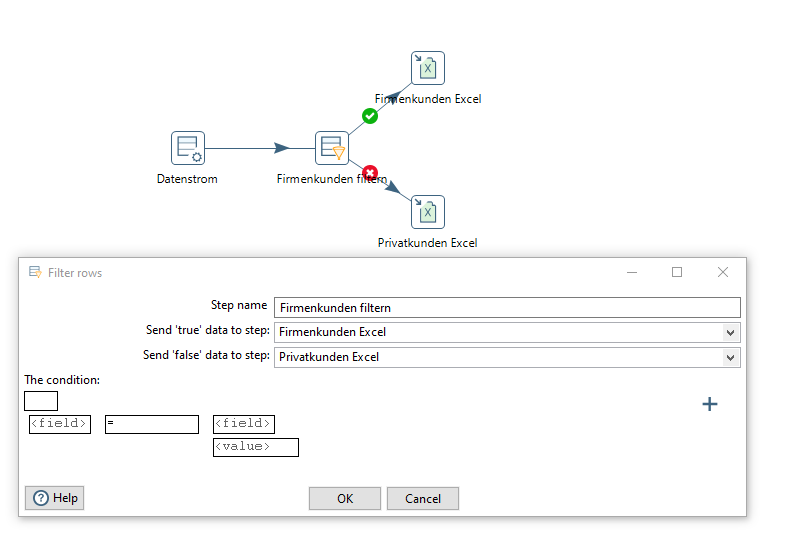
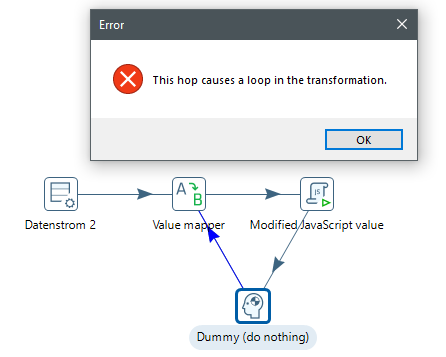
Ein Nachteil von Pentaho: es kann von Haus aus keine Schleifen und unterdrückt diese sogar nach Möglichkeit. Hier muss man dann schon tricksen oder auf externe Skripte z.B. in Python ausweichen.
Anwendungsfälle
Im IT-Datenmanagement werden viele verschiedene Aspekte des Programms genutzt.
Unser Hauptanwendungsgebiet ist der ETL Bereich, wie bereits im Blogpost „Der tägliche Wahnsinn eines Datenmanagers“ beschrieben, verarbeiten wir viele Daten von Banken, Dienstleistern und Partnern mit festen Jobs, um unter anderen Depotinformationen und Transaktionen bereit zu stellen.
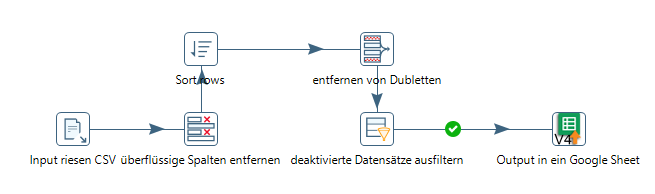
Mit diesem Werkzeug an der Hand kann man große Datenmengen schnell in handliche Pakete zerlegen, sie verändern, neu zusammensetzen oder die Quintessenz extrahieren und in Form von Auswertungen zur Verfügung stellen.
Aber auch außerhalb des klassischen ETL-Einsatzes kann Pentaho genutzt werden um schnell Auswertungen zu ziehen, zum Beispiel:
- Für Einmalauswertungen über die Vertragsdichte pro Kunde
- Ermittlung von Top-Vermittlern nach Geschäftsfeld und Gesellschaft(oder anderen Kriterien)
- Zuschneiden von großen Dateien, die man in Excel nicht mehr öffnen kann
- Aufgrund der Zeilenanzahl >~1 mio
- Aufgrund der Dateigröße. (z.B. eine CSV die über 1GB groß ist)
Hierfür bedienen wir uns an den verschiedenen Inputformaten.
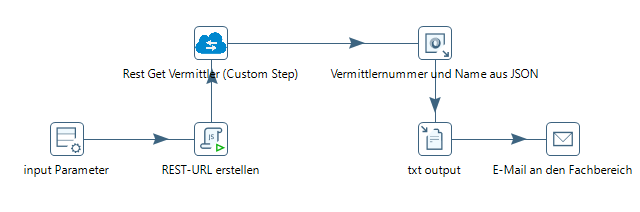
Häufig fragen wir für Statistiken unsere Microservices per REST-Client ab, verarbeiten das JSON weiter, erstellen eine CSV oder Excel und versenden diese, entweder manuell oder automatisch per Pentaho als E-Mail an die Kolleginnen und Kollegen im Fachbereich.
Abschluss
Pentaho hat sich bei uns im Datenmanagement aufgrund der Vielfältigkeit sehr bewährt.
Durch die verschiedenen verfügbaren Steps ist es uns möglich Daten in unsere REST-Services zu importieren und an anderen Stellen wieder für Statistiken zu exportieren.
Aber auch unsere Dateilogistik über verschiedene sFTP Server von Banken wird über Pentaho realisiert und in Datenbanken protokolliert.
Aufgrund des Aufbaus von Pentaho können wir außerdem die Jobs in einem eigens entwickelten Scheduler* ausführen, da jeder Job auch ohne GUI ausgeführt werden kann.
Wir freuen uns zukünftig tiefere Einblicke in unsere Arbeit gewähren zu können, in unserem Netfonds techblog.
*Upcoming: PDI Basics – Hands On (Step by Step bauen eines Jobs)
Pentaho Factsheet
- Java basiert
- Es können eigene Steps entwickelt werden
- Z.B. ein verbesserter Rest Client für unsere Servicewelt
- Marketplace mit Community Plugins
- Z.B. Google Sheets in- und output
- Einige Apache Module im Hintergrund
- Z.B. VFS (s.U.) für die sFTP Anbindung
- Google Anbindungen möglich
- Z.B. Bigquery
- Big Data Datenbanken können angebunden werden
- Machine Learning und Datamining
- Ansprechen von REST Schnittstellen
- Unterstützt verschiedene Inputformate: (die bei Netfonds gängigsten)
- JSON
- XML
- XLS / XLSX / XLSM (nicht nativ)
- CSV / TXT Klartextformate mit beliebiger Dateiendung und klarer Trennung
- Verschiedene Datenbanken, am häufigsten bei uns MySQL (besonders hervorzuheben: Google BigQuery)
- Salesforce
- Google Sheets
- Und verschiedene Outputformate: (die bei Netfonds gängigsten)
- CSV / TXT
- XLS / XLSX / XLSM (nicht nativ)
- Rest Put / Post
- Verschiedene Datenbanken, am häufigsten bei uns MySQL
- Salesforce
- Google Sheets
- Unterstützung von verschiedenen Programmiersprachen (teilweise nativ): (die bei Netfonds gängigsten)
- Java
- JavaScript
- Python
Inklusive unserer eigenen Steps ist unser Pentaho mit 244 Steps ausgestattet, wovon wir natürlich nicht alle nutzen.
Davon 3 Steps aus eigener Entwicklung und 6 ergänzt durch den in Pentaho integrierten Marketplace.
Glossar:
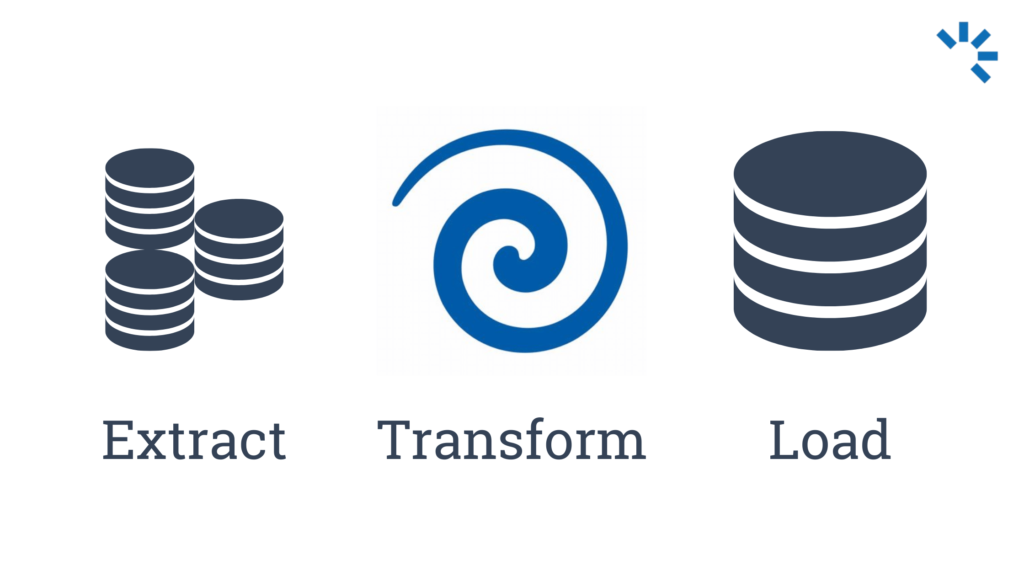
*ETL: Extract-Load-Transform:
E: Daten aus einer Quelle extrahieren, z.B. einer Datei oder Datenbank,
T: Daten aufbereiten z.B. über Mapper und Filter
L: Daten ins Zielsystem importieren
*VFS: Ein Virtuelles Dateisystem um z.B. einen sFTP wie ein Laufwerk handeln zu können. Lediglich als Abstraktion.
*Scheduler: Automatismus um Prozesse zu bestimmten Zeiten auszuführen. In unserem Fall konfigurierbar wie häufig und an welchen Tag der Job ausgeführt werden soll.
Bild: Canva, Pentaho

Vielen Dank für den Artikel! Ich lese mich aktuell in das Thema ETL ein. Da ich mich auch gerne praktisch engagieren möchte, ist es gut zu wissen, dass Pentaho eine gute Grundlage für ETL-Prozesse ist. Ich werde mal schauen, ob ich vielleicht über meine Universität an die Software komme.
Hallo Melanie,
Pentaho gibt es in 2 Versionen.
Die „Vollversion“ von Hitachi in einer kostenpflichtigen Version „Pentaho Enterprise Edition“. Hier sind einige Tools z.B. für die Automatisierung schon direkt mit enthalten.
Und die kostenfreie Version in der Community Edition unter der Apache 2.0 Lizenz.
Du solltest also auch für die Uni die „Pentaho Data Integration Community Edition“ (PDI-CE) nutzen können, vor allem um in das Thema mal reinzuschauen ist die Version ausreichend.
Als Communityversion gibt es außerdem z.B. den Report Designer um automatische Reports mit Grafiken zu erstellen, dieser ist bei uns jedoch nicht im Einsatz.
VG Dennis
Super geschrieben und das Thema sehr verständlich näher gebracht!