tl;dr
- Adding batch streaming source to an existing batch source is a complex undertaking, but less of a challenge compared to switching to a real time streaming solution.
- We decided to use a micro batch approach which updates the data every hour. This way we can reuse the existing code base.
- Planning out the different scenarios and data states and developing the ELT Jobs accordingly assures a stable operation.
- Using an insert overwrite strategy on historical data models can save you a lot with on demand pricing models of your database (we use bigquery).
finfire Analyses is the Business Intelligence Tool inside our web application finfire, which gives our customer a holistic view over all of their data. This application is powered by the Netfonds Data Platform. Since finfire is built as a microservice architecture, the data for each microservice governs is not accessible easily in any arbitrary way over microservice boundaries. But to answer analytical questions this is necessary. To access all the different data points stored in the microservices, we create a copy of the data in our data warehouse (DWH).
Usually we load fresh data via an ELT batch process once at night into our DWH. Since in today\’s world it is all about instant gratification. The same goes for data freshness. Our customers expect to see the changes they make reflect in our analytic applications asap.
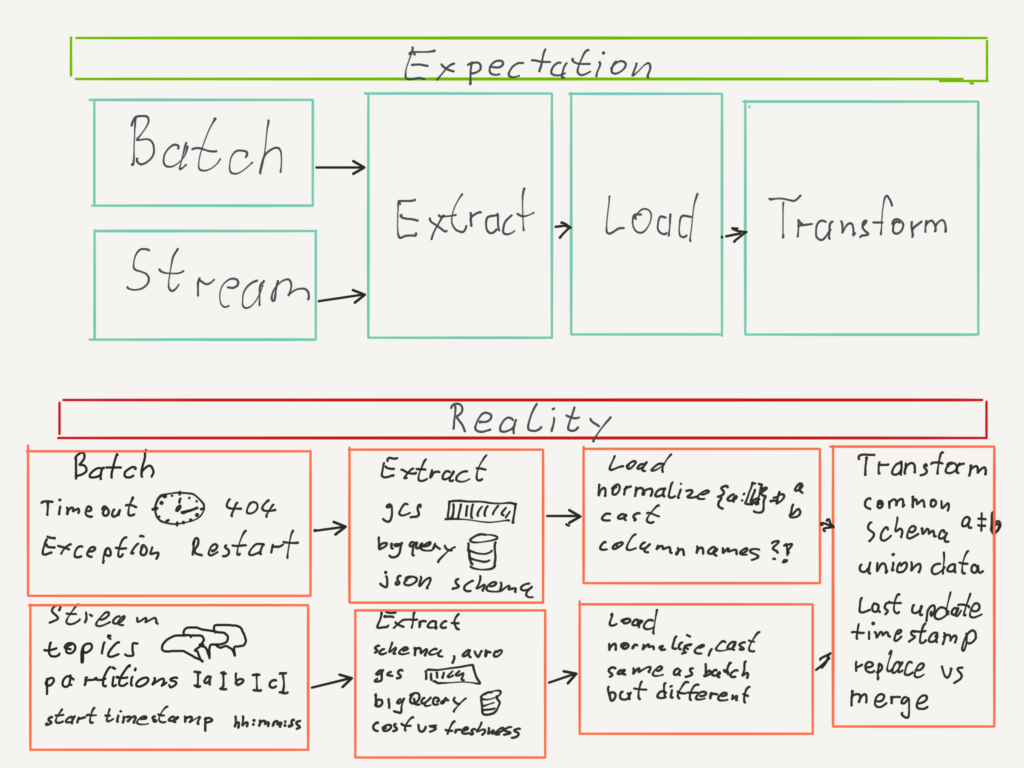
Batch load, micro batch, real time streaming
Before implementing any streaming solution it is good to evaluate the end user’s data freshness requirements. If a real time solution is necessary, your data stack most likely needs additional tools and jobs beside your batch processing. This can be a significant investment in labor and operation. We came to the conclusion that a refresh time frame of every hour ist enough. That means we can reuse our spark ETL batch jobs in a micro batch fashion without much modification.
There are two ways to get data out of our microservices. Either by using a REST API or consuming a kafka stream of change events. In this blog post we go over the challenges we face when ingesting streaming data into our data warehouse and how we solved them. As an example we take customer data from our customer microservice.
A customer is a data point with attributes like name, firstname, address and so on. The customer service has 3 kafka topics which are relevant for changes of customer data.
– kundenservice-kunde-create
– kundenservice-kunde-delete
– kundenservice-kunde-update
From the customer REST API and the kafka streams we want to build two target tables in our DWH for reporting purposes.
1. A table with our current customers with the newest information only.
2. A table with historical data per customer per day
The historical table is partitioned by day and we store all customers for every day with the latest status on that day. For example, if customer A on day1 lives in Wendenstraße and he moves to Heidenkampsweg on day2, then we have an entry in partition day1 with Wendenstraße and an entry in partition day2 with Heidenkampsweg of this customer. This data model allows us to easily query the data by day and answer questions like how many customers are updated each day.
The challenge is to develop a process (ELT Job) which creates our target tables. Our jobs should be easy to maintain, create reproducible results and should be resilient to errors. No job should create inconsistent results if something goes wrong. The steps (or tasks) in our job should have the following properties: idempotent, deterministic and the job itself should be easily recoverable in case of an error.
Idempotent and deterministic basically means that the task will produce the same result every time it runs or re-runs. For more information on this topic, I recommend this classic post.
Or even simpler, re-running anything from the whole job to a single step in your pipeline should never break your data integrity in your data warehouse.
With this design decision any data operator has the confidence to re-run jobs if something breaks, without the fear of making the situation worse.
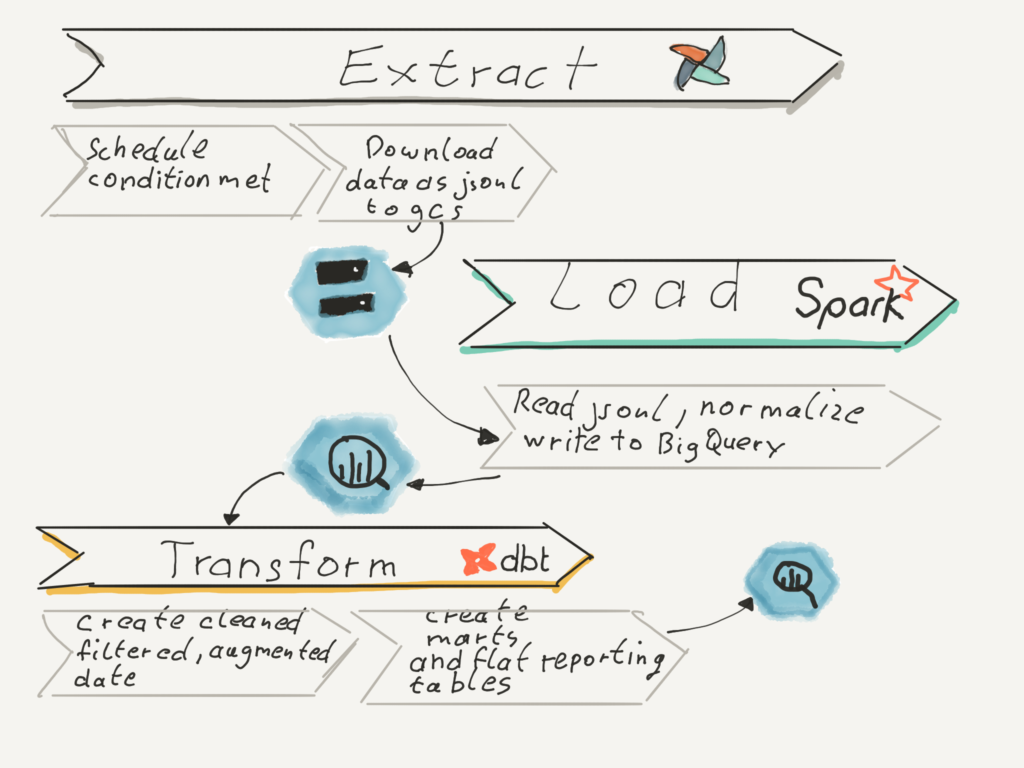
Our target architecture looks like this, which is similar to the lambda architecture for data ingestion:
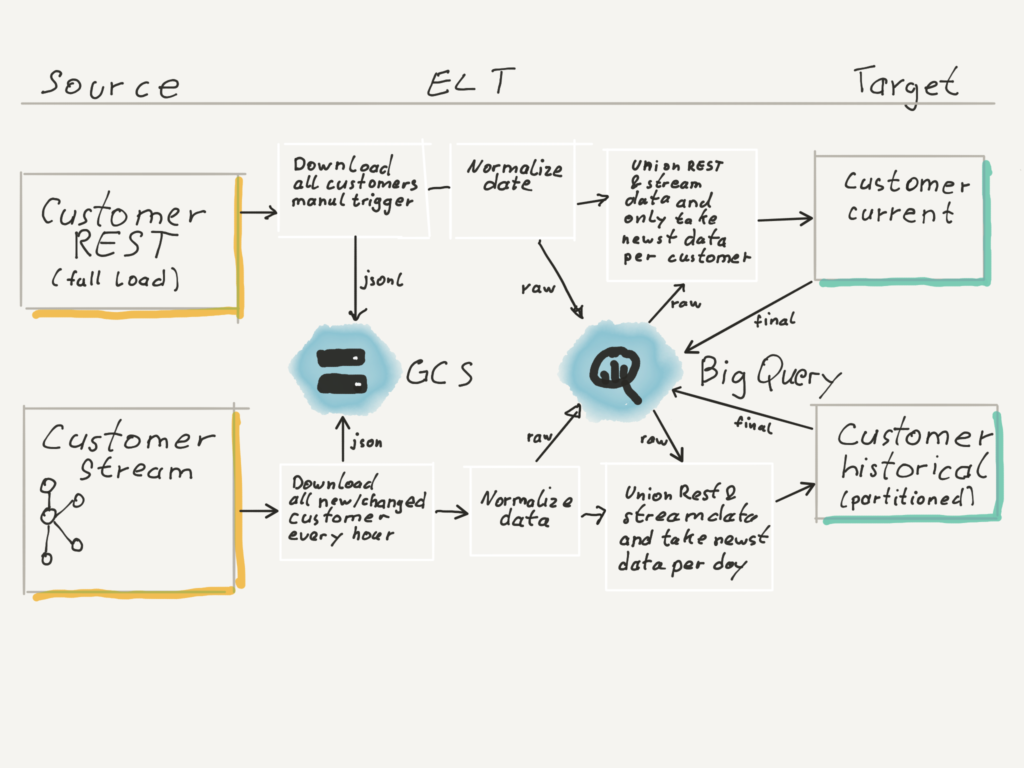
To achieve this, we have to consider some scenarios which might commonly happen when operating our ETL pipelines.
Scenarios to consider
When designing our micro batch job we have to cover the following scenarios or states our data can have:
| Scenario | Data states in target tables |
|---|---|
| Initial Full REST load | No data available, tables do not exists |
| Loading streaming data | Target tables with initial data from full load or with data from full and streaming exists |
| Full REST load in between | Target table exists with data from full load and streaming |
| Full rebuild of target tables | Target table exists with data from full load and streaming |
Initial Full REST load
This scenario happens if our Data Warehouse is completely empty.
- First we download a current snapshot of all customer data from the microservice as json. We store those json on google cloud storage and then process them with spark.
- The spark job does normalization and loads the data into our raw customer full table.
- From there we copy the data over to the current customer table.
- For the historical table the data is copied to the day on which we started the download of the data. We cannot take the day when the download finished, since the underlying data could be changed during download. Only for the day the download started we can say for all data that it is at least from that date and not older.
Loading streaming data
This scenario happens if we have data from the full load and start the micro batch streaming process.
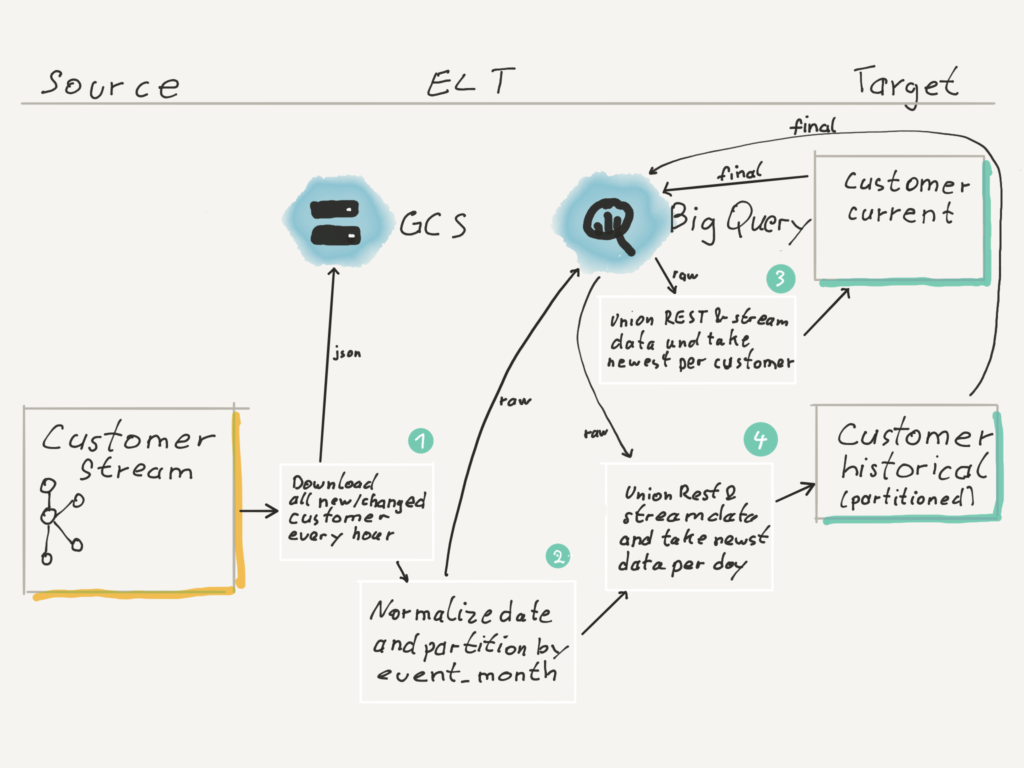
- We use the same spark job as for the REST data but instead we have a kafka streaming source. We download the data from all 3 topics in parallel. Each topic has the same schema. The delete topic actually is not really a delete topic (yet), but behaves like the update topic only containing an event when a customer is deactivated. If this would be a real delete event we would need to handle this differently.
We store the kafka events on google cloud storage, to be able to reprocess them, since the kafka system only holds events of the last 7 days. - After that we normalize the data and append it to our customer stream raw table. The table is partitioned by month. We do this since our customer data is very small and partitioning the table more granularly will not give any cost and performance advantage.
- Next we update the current customer table by selecting the latest data customer from the full load and all data newer than the full load from the streaming data. From this data we take only the newest data and then run a merge statement which only updates the necessary rows in the current customer table. We choose a merge statement here since we have no partitions in the current customer table. We clustered (in bigquery) the table by customer id to prevent full table scans on all source tables of the merge statement. That way we are still cheaper in terms of bytes consumed than completely recomputing the current customer table on every micro batch run.
- For the historical customer table we use an insert overwrite strategy. We recreate the current and last day of the historical customer table on every run. The last day to catch any changes between dates. The data is selected by querying the raw stream table only on the partitions which have data for the current and last day united with the latest raw current table.
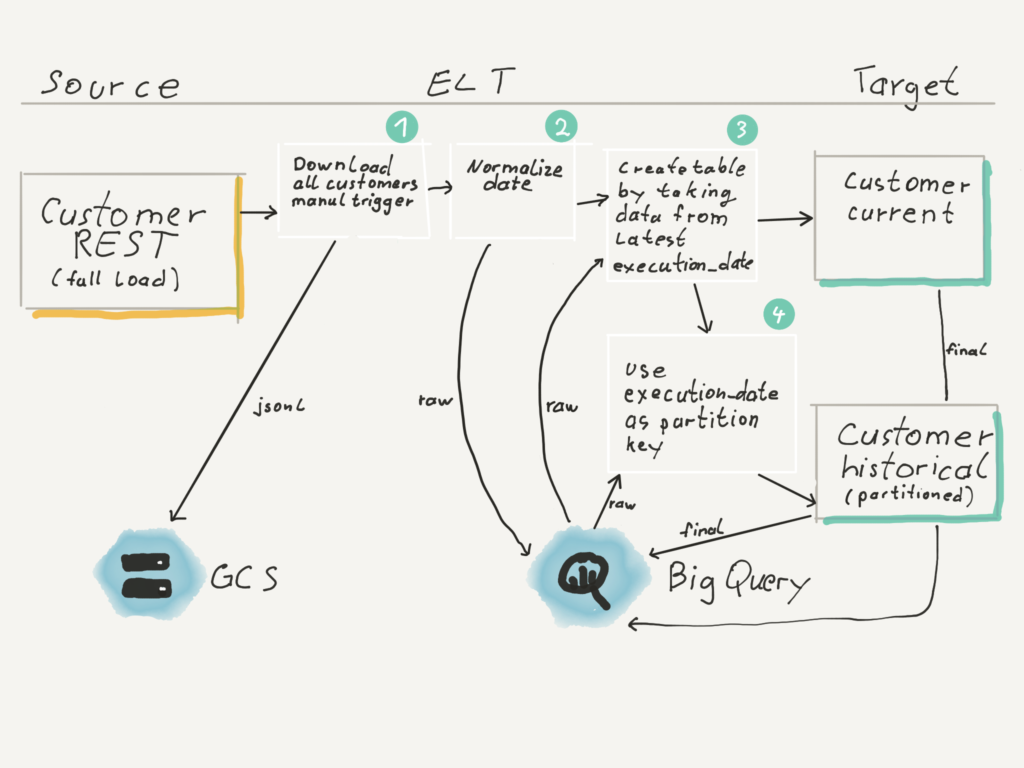
Full REST load in between
Sometimes the customer schema changes and new fields are added. Since they might get filled out inside the microservice with default values without emitting events in the kafka stream, we need to reload all data from the microservice. We run the same job as the initial Load job, but since we have to rebuild it, this time the dbt model for the current customer will be run with the flag --full-refresh.
For the historical table we just run the regular dbt model, because it always replaces the current and last day with a union of streaming and full load data. The exception would be if the runtime of the full load exceeded two days. Then we would have to trigger a full rebuild of the historical table or at least recompute more partitions.
Full rebuild of target tables
Let\’s assume we have our micro batch streaming solution running for a couple of months, just to find out that we are miscalculating a metric the whole time. In such a case we need to rebuild the current and historical table completely. For this reason we keep the raw data, so that we can rebuild our tables from scratch.
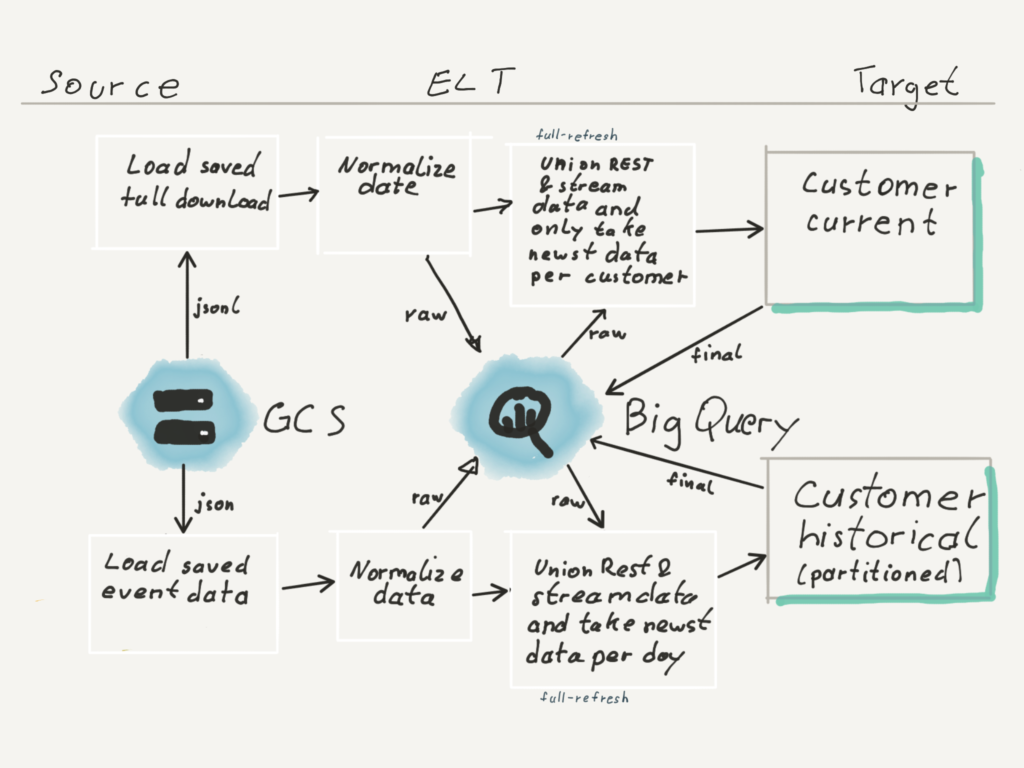
When developing the jobs, we made sure that there is a parameter which can be set to trigger a whole rebuild of the target tables from scratch.
Since our kafka stream only holds data for 7 days, we have a backup stored on google cloud storage (GCS), which is fed by our kafka micro batch job.
In case of a whole rebuild our spark kafka stream job is replaced by another spark job which loads all data from GCS instead of kafka and fills our raw tables. From here the dbt models are run with --full-refresh to recreate the target tables.
Future improvements
For streaming data we have not fully separated the extract and load parts from transformation, since it is all one spark job. Here a full dedicated EL tool like airbyte would be a better fit. Also most of our spark ELT jobs are taking up too much resources for the value they deliver.
Bild: Canva, Jan Erik