
Im letzten PDI Artikel haben wir vorgestellt, wozu PDI beim Datenmanagement der Netfonds AG u.A. genutzt wird.
Dieser Artikel richtet sich an Einsteiger und diejenigen, die mal einen Blick hinter die Kulissen werfen wollen.
Diesmal wollen wir zusammen mit Euch ein einfaches Rezept “kochen”. Dabei stelle ich Euch die Basics zur Bedienung von Pentaho vor und zeige, dass sogar einfache Prozesse durch Automatisierung verbessert werden können.
Let’s begin

Häufig werden in Unternehmen noch große Listen ausgedruckt, um diese danach vollständig händisch oder nach einem festen Muster in Excel zu bearbeiten.
Wann immer händische Arbeit im Prozess vorhanden ist, können sich auch Fehler einschleichen.
Aus dem Grund wollen wir uns heute anschauen wie eine Geburtstagsauswertung für das laufende Jahr aussehen kann. Mehr hierzu in der Aufgabenstellung.
Unser Werkzeug der Wahl ist in diesem Fall Pentaho.
Hier können wir feste Strecken bauen, die jedes mal gleich funktionieren.

Zutaten
1. Pentaho Data Integration Community Edition.
Im Beispiel genutzt: PDI-CE 8.2: https://sourceforge.net/projects/pentaho/files/Pentaho%208.2/client-tools/pdi-ce-8.2.0.0-342.zip/download
2. finfire Login zum Exportieren der Kundenliste.Alternativ sind die Steps auch grob mit einer eigenen Tabelle (csv/Excel) nachvollziehbar.
3. Für unsere Beispiele bewegen wir uns auf C:/input, dies kann schnell mit /input/ angesprochen werden.
Am Ende kann das fertige Gericht wie folgt aussehen:

Beispielaufgabe
Als Vermittler möchte ich an meine Kunden zum Geburtstag Glückwünsche und ggf. auch kleine Geschenke verschicken, um die Kundenbindung zu verstärken.
In finfire wird zwischen Interessenten und Kunden unterschieden, wobei Kunden in der Regel die Kontakte mit einer Geschäftsbeziehung darstellen.
Aus diesem Grund interessieren mich speziell die Kunden, und nicht die Interessenten.
Außerdem benötige ich eine E-Mail-Adresse oder eine Postversandadresse, um die Kunden zu erreichen. Für meine Vorausplanung genügen mir die Kunden, die dieses Jahr noch Geburtstag haben.
Daraus ergibt sich folgende Aufgabenstellung:
Gib mir…
- alle Kunden vom Typ “Kunden”
- die keine Firma sind, (Anrede != NONE)
- eine E-Mail oder Postadresse hinterlegt haben, (eines der beiden Felder befüllt)
- und dieses Jahr noch Geburtstag haben.
1.1) Intro
Wir fangen an, indem wir Pentaho öffnen und eine neue Transformation erstellen. Diese können wir an einem beliebigen Ort speichern.
Hierzu wollen wir eine Datei aus finfire einlesen, bearbeiten und die Ergebnisse als neue Datei ausgeben.Alle Schritte finden ausschließlich in Pentaho statt.
Die einzelnen Schritte sind in folgende Hauptkategorien gegliedert und teilen sich dann in einzelne, zu dem Step gehörende, Unterpunkte auf.
- Intro: Inhaltsverzeichnis und Grundlegende Pentaho Bedienung
- Textfile Inputs: Der Dateieingang mit dem unsere Transformation starten wird.
- Get system info: Mit diesem Step werden wir das Systemdatum einlesen, um einen Vergleichswert zu erhalten.
- Select Values: Hiermit passen wir die Spalten / die Metadaten der Datenfelder an, um auf das Datum filtern zu können.
- Filter Rows: Filtern der Datensätze von Leuten, die bereits Geburtstag hatten oder bei denen keine Adresse vorhanden ist.
- Excel Writer: Output der Zieldatei
1.2) Steps miteinander Verbinden
Die einzelnen Steps müssen gemäß des gewünschten Datenflusses miteinander verbunden werden.
Hierfür gibt es in Pentaho 3 Möglichkeiten:
A. Den ausgehenden Step auswählen (Textfile input finfire 2) und einen neuen Step per Doppelklick hinzufügen (Get system info)
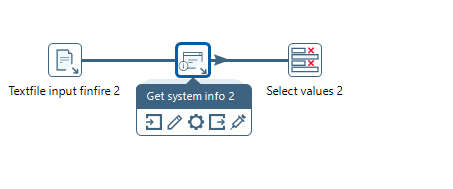
B. Per Verbindungspfeil entweder vom ausgehenden Step zum Zielstep verbinden oder vom Zielstep als Eingang den ausgehenden Step auswählen.
C. Den Step zwischen 2 Steps auf die Linie ziehen. Hierfür müssen zuvor 2 Steps bereits verbunden sein. Wenn ich nun einen 3. Step zwischen die beiden Steps ziehe und die Linie in Fett dargestellt wird, wird der neue Step als Schritt zwischen die beiden gehängt.
2.1) Textfile Input “File”
Um überhaupt Daten zum Arbeiten zu haben, müssen wir erstmal einen Input schaffen. Hierfür wählen wir anhand der Dateiendung einen passenden Step.
Die finfire Kundenlisten ist im .csv Format, ein Textformat mit definierten Trennzeichen und Zeilenumbrüchen.
Pentaho bietet 2 Steps für den Input an, den “CSV input” und den breiter aufgestellten “Textfile Input”, bevorzugt nutzen wir hier den allrounder Step – Textfile Input.
In diesem Step definieren wir zunächst die Eingangsdatei. Hierfür können wir verschiedene Formate verwenden:
- Pfad + Filename
- Pfad + Wildcard
- Pfad + Filename als Wildcard
Wildcard beschreibt hierbei eine Regular Expression.
Für einmalige Läufe empfiehlt es sich die Datei direkt auszuwählen. Wenn wir die Strecke wiederverwenden wollen, nutzen wir eine Regex.
In unserem Beispiel haben wir als Regex lediglich .* angegeben.

Regex ist eine Wissenschaft für sich, über Validatoren kann man feststellen, ob die verwendete Maske korrekt funktioniert. Im Regex-Schritt hat Pentaho einen eigenen Validator. Einfacher ist es jedoch einen Online Validator zu nutzen, dieser liefert in der Regel auch Erklärungen. Tipp vom Koch: https://regex101.com/ hat sich für mich hierbei als besonders nützlich erwiesen..
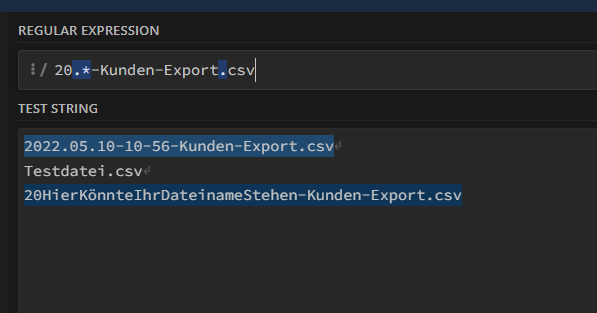
Zu erkennen ist auf dem Screenshot, dass der zweite Punkt ebenfalls als Regex erkannt wird. Ein Punkt steht hierbei für ein beliebiges Zeichen. Korrekt wäre es, diesen mit einem “\\” zu escapen.
Der Stern hinter dem ersten Punkt steht für eine beliebige Anzahl von Zeichen, so wird unser Dateiname erkannt, aber theoretisch auch jeder andere Text zwischen den festen Zeichen.
2.2) Textfile Input “Content”
Als nächstes stellen wir den Dateityp ein und wechseln dafür im selben Step auf den Reiter “Content”.
Dieser Reiter bietet uns einige Einstellungsmöglichkeiten für den Dateneingang.
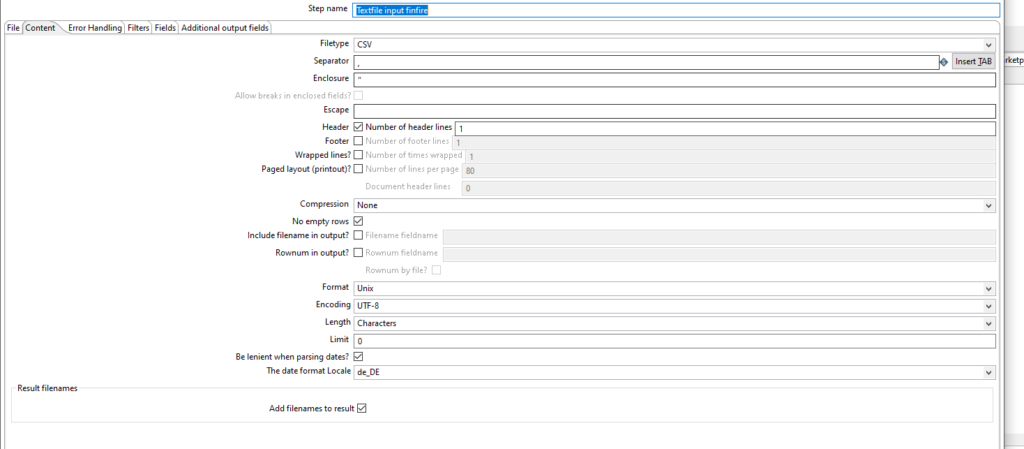
Im Fall vom finfire Kundenexport haben wir einen Separator* , und einen Enclosure* “.
Das Format muss auf Unix gestellt werden, hierbei geht es darum welcher Zeilenumbruch* genutzt wird (CF/LF)
Das Encoding ist in dem Fall UTF-8, damit die Umlaute richtig dargestellt werden.
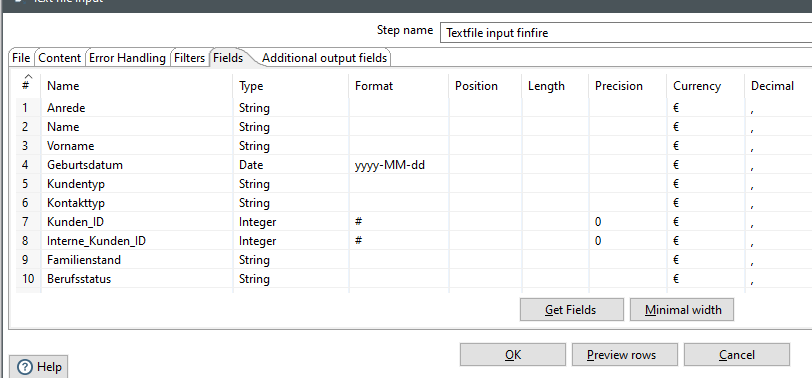
2.3) Textfile Input “Fields”
Abschließend wechseln wir im Textfile Input Step auf den Reiter “Fields”.
Dieser Reiter ermöglicht es uns die Felder zu konfigurieren, die geladen werden sollen und deren Format anzupassen.
Pentaho bietet hierfür die Get Fields Funktion. Sie liest den Dateiheader und die ersten X Zeilen aus und schlägt die passenden Feldtypen vor.
Vorsicht: Gerade bei den Längenangaben (length) ist hier Vorsicht geboten. Wenn in den Beispieldaten nur kurze Namen stehen, aber später in der Datei lange Namen vorkommen, kann dies zu abgeschnittenen Feldern führen.
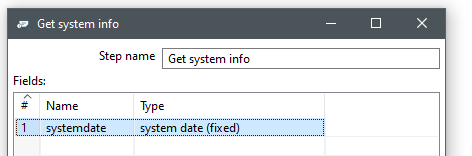
3.1) Get system info
Wir können in Pentaho einige Systemwerte auslesen, z.B. das aktuelle Systemdatum. Dieses nutzen wir als Vergleichswert für das Geburtsdatum.
Unter Type steht hierfür eine Auswahl zur Verfügung. Hier wählen wir system date oder eines der today formate.
Der Unterschied zwischen system date fixed und variable ist, dass beim fixed die Uhrzeit zum Transformationsstart gesetzt wird und beim variable die reelle Zeit gewählt wird, zu der die Datensatzzeile in dem Step ankommt. Da wir in unserem Beispiel die Sekunden und Stunden sowieso abschneiden, ergibt sich eine Auswahl aus system date oder today.
4.1) Select Values
Der Step “Select Values” hilft uns, überflüssige Spalten zu entfernen, zu duplizieren, umzubenennen und die Metadaten eines Feldes anzupassen.
Hierdurch können wir den Datenfluss verschlanken und die wesentlichen Informationen in den Fokus rücken.
Gerade bei großen Datenmengen kann sich dies positiv auf die Performance auswirken.
Wir wählen hierzu entweder jedes einzelne Feld aus, welches wir behalten wollen oder laden über “Get Fields” alle Felder und entfernen einzelne.
Hierfür klicken wir in der ersten Spalte “#” auf die Nummer und entfernen die markierte Zeile durch ein Drücken auf entf (Taste).
Alternativ können wir auch spezifische Felder über den Remove Tab entfernen.
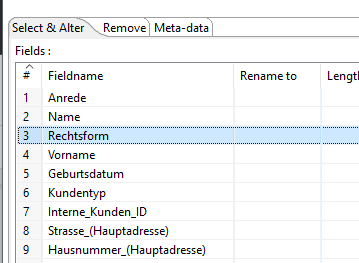
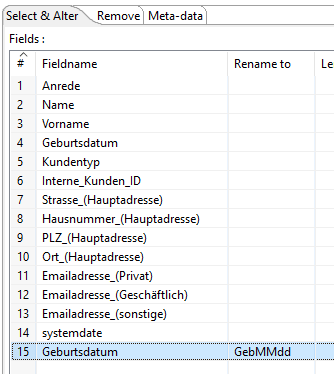
Jetzt entfernen wir alle Felder, die nicht Teil des Ergebnisses sein sollen und erhalten so die Felder, die wir für unsere Aufgabenstellung benötigen.
Außerdem fügen wir manuell am Ende ein zweites mal das Feld “Geburtsdatum” hinzu und benennen dies um in GebMMdd. Mit diesem Feld wollen wir unser Vergleichsdatum festlegen.
Der Step sollte dann auf dem Screenshot aussehen + ggf. weitere Felder nach eigenem Ermessen.
4.2) Select Values Meta-data
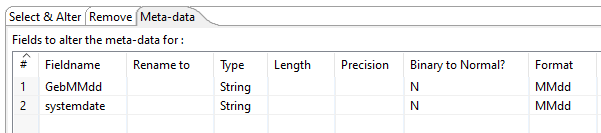
Im Reiter Meta-data können wir die Metadaten des Datensets konfigurieren und so z.B. den Feldtyp anpassen und festlegen in welchem Format das Feld dargestellt werden soll.
Damit wir in unserem Beispiel das Geburtsdatum ohne Jahr miteinander vergleichen können, müssen wir ein einheitliches Format schaffen.
Hierfür transformieren wir das Geburtsdatum und das Systemdatum zu einen String mit dem Format MMdd. Auf die Art wird das Jahr direkt entfernt und beide Felder sind im selben Format.
So wird aus 15.05.22 -> 0515.
5.1) Filter Rows allgemeines
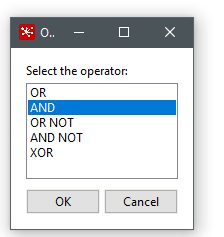
Der Step Filter Rows ermöglicht es uns, komplexe Bedingungen aufzustellen um Datensätze auszufiltern. Dieser Schritt bildet die Hauptzutat, um unsere Bedingungen zu erfüllen.
Die Bedingungen können verschachtelt werden und der Filter bietet für die Beziehung zwischen den Bedingungen folgende Standardoperatoren:
Zusätzlich können die Bedingungen auch noch negiert werden:
Mit Send true/false data to Step (unter dem Step name) kann festgelegt werden welche Daten über welchen Strom weiter verarbeitet werden. So können z.B. auch nur die false Daten weitergeleitet werden. Für unser Beispiel arbeiten wir mit true data. Über das Dropdown können alle verbundenen Folgesteps ausgewählt werden. Im Verbindungsmodus (Siehe 1.2b) können wir beim Verbinden auch direkt mitgeben, dass der true Ausgang genutzt werden soll.
5.2) Filter Rows Einstellung
Über die Bedingungen bilden wir jetzt die Aufgabenstellung nach.
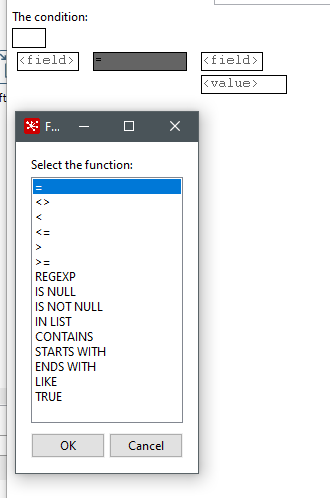
Hierfür können wir ein Feld auswählen und angeben ob wir dieses mit einen Value, einer Regex oder einen Feld vergleichen wollen. Hierzu gibt es bei dem “=” Zeichen eine Auswahl an Operatoren.
Über das + oben Rechts können weitere Bedingungen hinzugefügt werden.
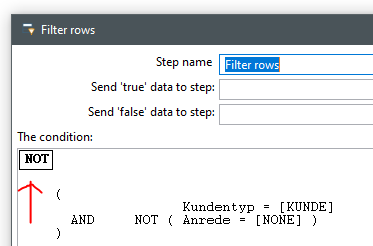
Der fertige Filter könnte dann wie folgt aussehen:
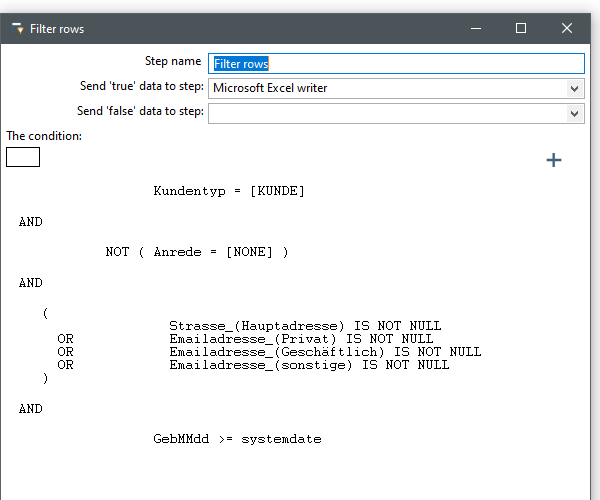
Der Filter besagt, dass der Kunde vom Typ Kunde sein muss UND die Anrede nicht NONE sein darf (Firma) UND das Geburtsdatum größer als das heutige Datum sein muss UND das Strasse oder eine E-Mail Adresse befüllt sein muss.
Wenn mehrere Felder befüllt sind, ist dies kein Problem.
Alle anderen Datensätze werden verworfen – an dieser Stelle könnten wir die Datensätze auch an den false Step weiterleiten, um z.B. zu prüfen ob wir die Datenqualität hier erhöhen können.
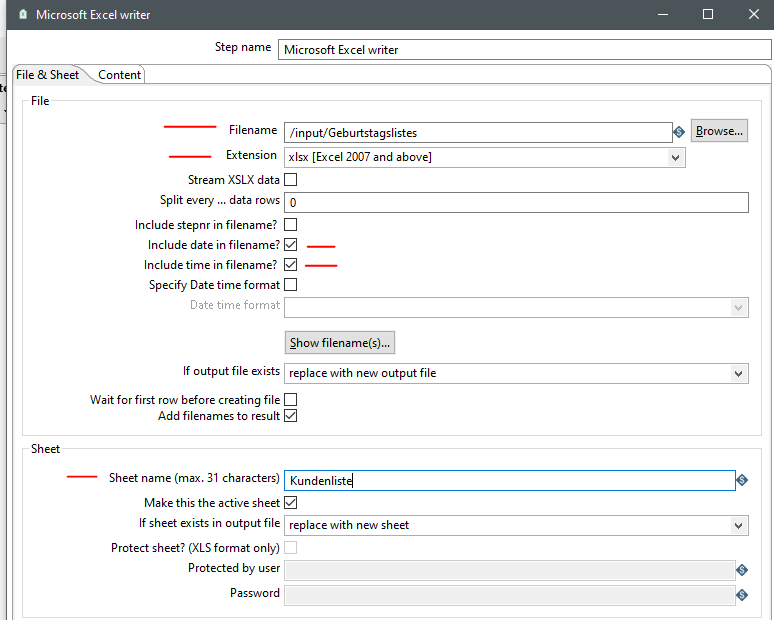
6.1) Excel Writer “File & Sheet”
Mit dem Excel Writer erzeugen wir zum Abschluss eine neue Exceldatei. Hierbei stehen uns sowohl das alte XLS Format als auch das neuere XLSX Format zur Verfügung.
Außerdem können wir automatisiert das aktuelle Datum und/oder die Uhrzeit an den Dateinamen anhängen.
Unter Sheetname geben wir den Namen des Tabellenblatts an. In unserem Beispiel soll der Tabellenblattname Kundenliste sein.
6.2) Excel Writer “Content”
Im Content Tab bestimmen wir, welche Spalten in die Excel-Datei geschrieben werden sollen. Dies bietet uns die Möglichkeit, unsere Systemzeit und das Hilfsfeld Geburtsdatum zu entfernen.
Über den Get Fields-Knopf können wir auch hier wieder die Liste vorbefüllen und anschließend Felder nach eigenen Ermessen entfernen oder umbenennen.
Ergebnis:
Der Job kann jetzt, sofern eine Liste aus finfire vorliegt, in einem beliebigen Intervall ausgeführt werden und filtert die Datensätze automatisch nach einem festen Prinzip.
Aus 39 Inputspalten und 105 Zeilen werden 13 Outputspalten und 17 Zeilen. Nach Belieben kann z.B. auch für die ausgefilterten Zeilen eine Outputdatei zusätzlich oder anstelle erstellt werden.
Abschluss
Ich hoffe, das heutige Gericht hat euch gefallen und animiert euch zum Nachkochen.
Dieses einsteigerfreundliche Rezept zeigt auf, dass Pentaho nicht nur ETL Prozesse, sondern auch Sachberarbeitertätigen automatisieren kann.
Alte Excel Makros oder Formelsammlungen gehören mit den richtigen Tools der Vergangenheit an.
Glossar
Separator: Der Separator gibt an, wie die Felder voneinander getrennt sind. Die am häufigsten verwendete Dateiart ist CSV (Comma Separated Value). Trotz des eindeutigen Namens können neben “,” bspw. auch TAB als Trennzeichen bei einer CSV verwendet werden.
Enclosure: Da ein Trennzeichen auch in einem Datensatz vorhanden sein kann, benötigt man eine Möglichkeit, das gesamte Feld als solches einzuschränken.
Wenn wir z.B. die Firma “Test, Bau GmbH” betrachten, stellen wir fest, dass diese ein Komma enthält. Wenn unser Trennzeichen ein Komma ist, würde dieser Datensatz hier getrennt werden. Der Enclosure markiert den Anfang und das Ende eines Strings. z.B. durch ein “ . Auf diese Art wird der Inhalt im Feld nicht aufgetrennt, nur weil ein Trennzeichen vorhanden ist.
| Datensatz ohne Enclosure | Datensatz mit Enclosure “ | |
| Input mit Komma getrennt | Firma, Test, Bau GmbH, teststraße 11 | “Firma”, “Test, Bau GmbH”, “teststraße 11” |
| Output mit Seperator “,” und Enclosure “ – wenn vorhanden | Firma Test Bau GmbH teststraße 11 | FirmaTest, Bau GmbHteststraße 11 |
Zeilenumbruch: Aus der Computerhistorie gibt es verschiedene Zeilenumbrüche. Das sind in der Regel nicht sichtbare Steuerzeichen am Ende einer Zeile.
Das erstellende System legt hierbei den Zeilenumbruch fest.
In Pentaho haben wir
DOS: LF & CR
UNIX: LF
MIXED: Nicht genauer spezifiziert wie LF & CR auftreten.
Der Ursprung der Terminologie liegt bei den Schreibmaschinen, da der Wagen hier zurückgeschoben und in die nächste Zeile verschoben wurde.
LF = Line Feed (Zeilenvorschub)
CR = Carriage Return (Wagenrücklauf)
Bild: Canva, Pentaho

Chapeau Dennis! Ich habe das Gefühl ich kann das jetzt auch…und das auch gut dokumentiert und für andere verständlich. Weiter so!